Cara Kerja Machine Learning
Pada beberapa bagian sebelumnya kita telah mengenali beberapa algoritma machine learning. Agar lebih memahaminya sebaiknya kita mengetahui bagaimana cara kerja machine learning itu. Machine learning pada awalnya bekerja dengan cara belajar yang bertujuan untuk menghasilkan model tertentu. Model yang telah dibentuk itu nantinya akan menjadi informasi untuk pemecahan masalah baik dalam proses input maupun output. Kemudian model tersebut dapat memprediksi atau mengelompokkan data pada kedepannya.
Baca juga : Belajar Data Science: Pahami Penggunaan Machine Learning pada Python
Terapkan Contoh-Contoh dari Algoritma Machine Learning Bersama DQLab
Jika kamu ingin tahu lebih mengenai tipe algoritma-algoritma Machine Learning serta ingin belajar secara langsung, DQLab adalah solusi yang tepat. Caranya mudah, kamu bisa memulainya dengan membuat akun GRATIS di DQLab.id/signup. Nikmati pengalaman belajar Data Science yang menarik bersama DQLab yang seru dan menyenangkan dengan live code editor yang simple. Selain itu, kamu juga bisa mengerjakan free module Introduction to Data Science with R dan Introduction to Data Science with Python untuk menguji kemampuan Data Science kamu. Yuk persiapkan dirimu untuk berkarir sebagai praktisi data yang kompeten!
Penulis : Salsabila Miftah Rezkia
Editor : Annissa Widya Davita
%PDF-1.7 %µµµµ 1 0 obj <>/Metadata 836 0 R/ViewerPreferences 837 0 R>> endobj 2 0 obj <> endobj 3 0 obj <>/ExtGState<>/ProcSet[/PDF/Text/ImageB/ImageC/ImageI] >>/Annots[ 13 0 R 14 0 R 15 0 R] /MediaBox[ 0 0 595.32 841.92] /Contents 4 0 R/Group<>/Tabs/S/StructParents 0>> endobj 4 0 obj <> stream xœ½][s䶱~ߪý󒪙”‡"@ $S©Tv½vöboœìæäÁÉW¢¤YÍŒ µŽþýA7.¼ � —-K$H~h4ú†FãäÕm·9oN»ÅÿxòªëšÓËölñëÉç뛟|¾¿iO~i.6û¦Û\ïO>Ý}éàÒÛ¶9koÿô§Åë7ß/þóòEžåðOU•d‘/xͳ‚.*F²š.nÛ—/þùûÅþå‹×Ÿ_¾8ù‘,ꬋÏç/_@ã|AÏHÎUÎ2ÊŸw²Ù_>•‹‹ƒ|óâÿªô_yùâ×åûÕš/ïn÷Íj],·‹Õ¿Ÿß¿|ñƒ|ýß^¾8!<«Gp…þø»U±ÜŸ_¯ÖÕò¶ í)À¸œ—(B Žë3 AYÓ¬¤ÎçþOvW,·w«5[îàG;; Bä¥Ð÷Åì_£†8ð¹ù;GËŒ‰Ðç>"u³U�àÃŒe‚†>Læÿ\�‰`?ç里BŸ{/'êLÐ=üØÌþqQeÕÿ°¯%ÉhàsùnÙúô×%ÍgÿnE²"8SèüŸ Ê6ûçjIU9ˆnAYÖÊËLTRve\}îü÷s cIzÔsÓ H@C_[Ïþ5–ñ*ôµw I?}Z±åÇ?$Â…°ç˃ T>¿T$(„ÿ7‘_ù»ùë²QHà‡X‰åüÂB°¬¬ß~î€þG¿¦*¤n�™WfbÁ¸È8—ãÆ*;ñþ†ÿ.~øùûÅIÀª}}Ýu×»°aûãõu÷\Ã6<‘‹J²—kÄ]Â8tÝ 0ýNNÚ¯×ðª¬[ø õV³Íà÷/ðûAj´M†VïifØæ~Ê'ïähžY‘|¹=Ùìç_JªLÔ¡þœ¡5üßÕº”ÆÌš.oàïK‰8à9ü¸6p»öô8ÃÙ²ª39»Xá´ÊJÿ×z±Âf·`¹ü¢œj©z9þ–lFfÿÖd^³*+¤bè'vY×Þ¹½8ùtÓìabÿüý»7‹üä§f±X¶ûõ?>žë“ê|$ËŠ\ŽkÉŠ¬tûü0o{ûeU-q:îϤõ¾Q°^^À/êúbEÈòú©R«]Èÿp’ßʱy·“—°éqCVxz@+y©uág T‰’K‹½E¸?açL×nM¯T“‹ã±ú¨]Ô"#A¬7ë™ùe~ŒÖ ø°]�\eR˯o”$Ócxe@äýM"t’>Œ†ÐM¾ç›&$Ñ4¡\’X”ÒÕžŸžìï “_>ê £Þ÷EÞèîìäIÀ`Ò]#$„3‚€4é=Ô’€àDTÏVh`ç›õ�ïž ÌU£”g‚/D]K÷À#=Øòî°BK…È Ñ€!Ò¡ý²—· ÿ?6׸�{tóu„ÍÒ&áˆÀ¹4J%�séã=ñÁâ©`•Y]`ýþqX"Í°;J�80ìßÁPâà~º“ÃüUC077joo1@ˆjc¹B1Èþñn•‰¨-ýÎ*Dmú8¬*µë*£EˆÚ“¿NÇR(‰ªô�+FÛä3à¢î0Ò¼ D”µOŠGLfBfæJË\ ÁJ–²7®±ÝY÷.†‚4Pé®0úCÑâ¿‘>‚í`.³ÁÔÿÇm¾á<5~«Œ9Ë»þ‡^ƒ1´‡6Í~~j°Y³ÿP]zg=Ö±Wˆß—Žù•rf§Õ*ÐC+Fs0 ´ŠÄ9TšoË^ºM¾iÐF ›C©y�Õ/BÀÖÀæPk>`œfU�bŠá6ÛiÐÑ‹p åCXr” ¼3A ¥\›®_ÞÀ€‹�·Yú³´Î‚a£Ç»9‡Æót³(«¬DýçPy>`ÁÉþl`t�Ôż€ ç ›Gç9ʘÔ'»Fã%¨¢‰t‘”¥F|Îòg˜*í¨!œ:×ðc{½*ÁõäËÍâ4À«OW„ÕDö¿T„4•",š©~‚Æ°`*EÈ•·Rä>ŒP„4•"äÊ{ö‹P„4™"¬³
Algoritma machine learning adalah metode dimana sistem artificial intelligence mengerjakan tugasnya secara otomatis. Umumnya algoritma machine learning ini digunakan untuk memprediksi nilai output dari input yang diberikan. Dua proses utama dari algoritma machine learning adalah klasifikasi dan regresi. Algoritma machine learning sendiri dibagi menjadi dua, yaitu supervised dan unsupervised learning. Supervised learning membutuhkan data input dan data output yang diinginkan dan digunakan untuk membuat pelabelan, sedangkan algoritma unsupervised learning bekerja dengan data yang tidak diklasifikasikan atau tidak diberi label. Contoh algoritma unsupervised learning adalah pengelompokan atau clustering data yang tidak difilter berdasarkan persamaan dan perbedaan. Pada artikel kali ini, kita akan membahas algoritma supervised learning, yaitu algoritma klasifikasi.
Terkadang sulit memutuskan algoritma machine learning mana yang paling baik untuk klasifikasi diantara banyaknya pilihan dan jenis algoritma klasifikasi yang ada. Namun, ada algoritma klasifikasi machine learning yang paling baik digunakan dalam masalah atau situasi tertentu. Algoritma klasifikasi ini digunakan untuk klasifikasi teks, analisis sentimen, deteksi spam, deteksi penipuan, segmentasi pelanggan, dan klasifikasi gambar. Pilihan algoritma yang sesuai bergantung pada kumpulan data dan tujuan yang akan dicapai. Lalu apa saja algoritma klasifikasi terbaik tersebut? Yuk simak artikel kali ini hingga akhir!
Mulai Belajar Menjadi Data Scientist dari Sekarang!
Tahukah kalian bahwa data scientist kini sangat banyak diminati oleh berbagai kalangan. Data scientist merupakan profesi terseksi di abad ini serta gaji dan jenjang karirnya pun cukup menjanjikan. Jadi, Untuk mengetahui lebih lanjut terkait data scientist kita dapat mempelajarinya di DQLab lohh. Caranya sangat mudah, yaitu cukup signup di DQLab dan nikmati momen belajar gratis bersama DQLab dengan mengakses module gratis dari R, Python atau SQL!
Penulis : Latifah Uswatun Khasanah
Editor : Annissa Widya Davita
K-Means Clustering
Seperti namanya, algoritma ini biasa digunakan untuk kasus clustering. K-means Clustering adalah salah satu contoh algoritma Unsupervised Machine Learning yang paling sederhana dan populer. Metode K-Means Clustering berusaha mengelompokkan data yang ada ke dalam beberapa kelompok, dimana data dalam satu kelompok mempunyai karakteristik yang sama satu sama lainnya dan mempunyai karakteristik yang berbeda dengan data yang ada di dalam kelompok yang lain.
Cara kerja algoritma ini mula-mula adalah dengan membentuk sejumlah k titik, yang disebut dengan centroid (dimana nilai k merepresentasikan jumlah cluster). Kemudian titik-titik data (data points) yang ada akan membentuk cluster dengan centroid terdekat darinya. Otomatis, titik pusat (centroid) akan berubah seiring dengan pertambahan anggota tiap cluster-nya (yang mana adalah data points tadi). Oleh karena itu, tiap-tiap cluster yang telah terbentuk akan mencari titik centroid barunya. Proses ini terus menerus dilakukan hingga diperoleh kondisi konvergensi, contohnya jika posisi centroid sudah tidak berubah.
Terdapat dua jenis data clustering yang sering dipergunakan dalam proses pengelompokan data yaitu Hierarchical dan Non-Hierarchical, dan K-Means merupakan salah satu metode data clustering non-hierarchical atau Partitional Clustering.
Decision Tree adalah salah satu metode klasifikasi yang paling populer, karena mudah untuk diinterpretasi oleh manusia. Decision Tree adalah model prediksi menggunakan struktur pohon atau struktur berhirarki. Algoritma Machine Learning jenis ini melakukan tugasnya dengan menggunakan konsep struktur flowchart bercabang menggunakan decision rules atau aturan-aturan keputusan yang dibuat oleh desainernya.
Pada dasarnya, Decision Tree dimulai dengan satu node atau simpul. Kemudian, node tersebut bercabang untuk menyatakan pilihan-pilihan yang ada. Selanjutnya, setiap cabang tersebut akan memiliki cabang-cabang baru. Maka dari itu, metode ini disebut "tree" karena bentuknya menyerupai pohon yang memiliki banyak cabang. Mengutip dari Venngage, Decision Tree memiliki tiga elemen di dalamnya, yaitu:
Root node (akar), Tujuan akhir atau keputusan besar yang ingin diambil.
Branches (ranting), Berbagai pilihan tindakan.
Leaf node (daun), Kemungkinan hasil atas setiap tindakan.
Dalam Machine Learning kita akan sering mendengar tentang metode Random Forest yang digunakan untuk menyelesaikan permasalahan. Metode Random Forest merupakan salah satu metode dalam Decision Tree. Random Forest adalah kombinasi dari masing-masing tree yang baik kemudian dikombinasikan ke dalam satu model. Random Forest bergantung pada sebuah nilai vector random dengan distribusi yang sama pada semua pohon yang masing masing Decision Tree memiliki kedalaman yang maksimal.
Oleh karena itu, prinsip dasar random forest mirip dengan Decision Tree. Masing-masing Decision Tree akan menghasilkan output yang bisa saja berbeda-beda. Nah, Random Forest ini akan melakukan voting untuk menentukan hasil mayoritas dari semua Decision Tree. Sederhananya, Random Forest akan memberikan output berupa mayoritas hasil dari semua Decision Tree.
Baca juga : Machine Learning vs Deep Learning Korelasi AI, Machine Learning dan Deep Learning
Logistic Regression
Logistic Regression atau Logit Regression adalah algoritma klasifikasi untuk mengklasifikasikan data ke dalam dua kategori. Istilah regresi sebaiknya tidak disalahartikan sebagai regresi dari supervised learning karena regresi dalam Logistic Regression mengacu pada Generalized Linear Model (GLM) dengan Fungsi Logit.
Model ini adalah salah satu model paling sederhana dalam algoritma klasifikasi dan digunakan dalam banyak contoh real-case seperti prediksi penyakit, prediksi churn, prediksi repeat-order, dan banyak kasus penggunaan klasifikasi lainnya.
Mengenai persamaannya, GLM adalah model kelas luas yang mencakup banyak model, misalnya: Linear Regression, ANOVA, dan Logistic Regression.
Logistic Regression mengikuti tiga komponen dasar GLM, yaitu:
Gambar 3. Struktur dasar GLM
Random Component (E(Y)): Ini adalah distribusi probabilitas model Logistic Regression (Variabel Respons), dalam hal ini, Binomial distribution atau lebih tepatnya, probabilitas keberhasilan suatu peristiwa (E(Y) = 1).
Systematic Component: Ini adalah variabel-variabel penjelas (x1, x2, …, xn) dalam prediktor linear (+1 X1 +2X2 + … + nXn).
Link Function (g()): Ini adalah fungsi yang menghubungkan nilai yang diharapkan (E(Y))) dari variabel terikat pada prediktor linier. Linear Regression menggunakan Fungsi Logit, yaitu log(P/1-P) di mana P adalah Probabilitas Keberhasilan (E(Y) = 1). Dengan Fungsi Logit, hasil diharapkan berada antara 0 hingga 1.
Semua struktur di atas akan membuat model yang disebut Logistic Regression.
Decision Tree adalah model klasifikasi di mana proses pembelajaran adalah metode untuk mendekati fungsi target diskrit yang direpresentasikan oleh decision tree. Kata tree merujuk pada mathematical graph theory, yang didefinisikan sebagai grafik tidak berarah di mana dua simpul (node) terhubung oleh satu jalur (path).
Sederhananya, decision tree adalah model klasifikasi untuk mengelompokkan data berdasarkan struktur pohon terbalik. Decision tree akan membuat simpul yang terus membagi berdasarkan pembelajaran data dan akan berhenti sampai parameter yang telah kita tentukan atau tidak ada lagi pembagian yang terjadi. Contoh decision tree ditunjukkan dalam gambar di bawah ini.
Gambar 4. Contoh Decision Tree
Bagaimana decision tree menentukan fitur dan nilai apa yang akan dibagi? Ada beberapa algoritma dalam pengambilan keputusan, tetapi yang umum adalah Gini Index, Entropy and Information Gain metrics. Ide dasar penggunaan kedua algoritma pembagian adalah untuk mengukur seberapa baik pembagiannya berdasarkan nilai yang kita bagi dan hasilnya. Perhatikan gambar di bawah ini untuk memahami bagaimana algoritma menentukan titik pembagian terbaik.
Gambar 5. Penentuan titik pembagian decision tree
Gambar di atas menunjukkan di mana X1 berada dalam dua nilai, dan nilai Information Gain (IG) berbeda. Pembagian terbaik adalah ketika IG lebih tinggi, sehingga X1 = 2 adalah titik pembagian terbaik. Pembagian terus berlanjut sampai simpul hanya memiliki satu kelas atau memenuhi hyperparameter yang telah kita atur.
Decision tree adalah salah satu model yang populer digunakan oleh banyak ahli data karena cepat dan mudah dijelaskan. Namun, model ini mengalami banyak masalah overfitting. Itulah mengapa banyak model dikembangkan dengan decision tree sebagai dasarnya — misalnya, Random Forest.
Random Forest adalah algoritma klasifikasi yang didasarkan pada decision tree. Nama random berasal dari randomisasi yang diperkenalkan dalam algoritma, dan nama forest berasal dari beberapa decision tree yang membangun model tersebut.
Sebelum kita membahas random forest , kita perlu memahami konsep ensemble learning karena model random forest diklasifikasikan sebagai salah satu dari mereka. Ensemble Learning adalah konsep dimana kita menggunakan beberapa algoritma untuk mencapai hasil prediksi dan kinerja yang lebih baik. Misalnya, kita menggunakan beberapa algoritma decision tree untuk membangun model random forest.
Tepatnya, random forest diklasifikasikan sebagai bootstrapping aggregating (bagging) ensemble. Apa itu bagging, dan bagaimana model bekerja? Pertama, kita perlu memahami konsep bootstrap dalam statistik. Bootstrap adalah metode untuk pengambilan sampel acak dengan penggantian; dengan kata lain, kita membuat dataset baru dari dataset yang sama dengan pengulangan. Perhatikan gambar di bawah ini untuk memahami bootstrap.
Gambar 6. Contoh Bootstraping
Gambar di atas menunjukkan bagaimana bootstrap bekerja. Kita memperlakukan data asli sebagai kolam, mengambil sampel ulang data dari sana, dan setiap dataset yang di-bootstrap bisa berisi nilai yang sama. Contoh di atas menunjukkan dua data yang di-bootstrap dengan tiga sampel untuk setiap dataset.
Kita akan menggunakan beberapa decision tree yang secara eksplisit dilatih dengan data yang di-bootstrapped dalam model random forest. Untuk setiap decision tree yang kita gunakan, kita melatih pada data bootstrap yang berbeda. Jadi, jika kita memiliki 100 decision tree dalam random forest, kita akan melatih 100 decision tree dalam 100 data bootstrap yang berbeda.
Kita menggunakan metode bootstrap untuk memperkenalkan ke-random-an ke dalam model dan menghindari overfitting karena data bootstrap akan memiliki estimasi distribusi yang serupa dengan data asli tetapi berbeda. Proses ini akan memastikan terjadinya generalisasi.
Selain itu, untuk menghindari overfitting lebih lanjut, algoritma random forest dapat mengurangi jumlah fitur yang akan dipertimbangkan saat membuat data bootstrap.
Seringkali, ini adalah akar kuadrat total fitur dari data asli; jadi jika data asli kita memiliki empat fitur, kita akan menggunakan dua fitur dalam data bootstrap kita. Pemilihan fitur juga dilakukan secara acak untuk menghindari overfitting lebih lanjut.
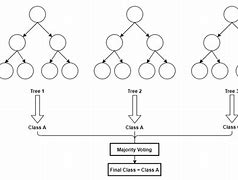
Pada akhirnya, setiap decision tree akan memiliki output probabilitas. Output dari random forest akan menjadi rata-rata dari setiap decision tree. Gambar di bawah ini merangkum algoritma random forest.
Gambar 6. Algoritma Random Forest secara umum
Naive Bayes adalah algoritma klasifikasi berdasarkan Teorema Bayes ( Bayes Theorem). Berbeda dengan frequentist theorem, di mana probabilitas suatu peristiwa didasarkan pada data saat ini, Teorema Bayes akan memperbarui probabilitas berdasarkan probabilitas sebelumnya (prior probability).
Sebagai contoh, kita mengasumsikan bahwa probabilitas hujan adalah 50% ketika cuaca cerah, tetapi setiap hari kita memperbarui probabilitas dengan setiap informasi yang tersedia. Probabilitas Teorema Bayes dapat dijelaskan dalam gambar berikut.
Gambar 7. Persamaan Theorema Bayes
Gambar di atas menunjukkan Teorema Bayes di mana:
P(A|B) adalah probabilitas posterior (Probabilitas peristiwa A terjadi jika B benar)
P(B|A) adalah probabilitas peristiwa B terjadi jika A benar. Kita juga bisa mengatakan ini adalah peluang (likelihood) A akan terjadi jika B tetap.
P(A) dan P(B) adalah prior probabilities; tanpa syarat apapun atau bila tidak ada bukti, seberapa besar kemungkinan terjadinya peristiwa A atau B.
Sehubungan dengan dataset, kita dapat menyatakan persamaan awal Naive Bayes seperti gambar di bawah.
Gambar 8. persamaan awal Naive Bayes
Mari kita ambil contoh dari dataset sebelumnya dan katakanlah X = (Width = 15, Weight = 100, Color = Red) dan y = Apple. Jadi kita bisa menyatakan bahwa pengklasifikasi Naive Bayes P(y|X) adalah probabilitas Apple diberikan Width = 15, Weight = 100, dan Color = Red. Untuk menghitung probabilitas, biasanya algoritma Naive Bayes memerlukan data kontinu untuk diskritisasi atau menggunakan estimasi densitas probabilitas. Tetapi untuk contoh kali ini, mari kita anggap mereka adalah kategorikal.
Jika kita masukkan semua informasi dari data kita ke dalam algoritma Naive Bayes, maka akan seperti gambar di bawah ini.
Gambar 9. Perhitungan Apel dengan Naive Bayes
Kita memasukkan informasi pada data yang kita miliki. Untuk P(Apple) atau prior adalah kemunculan label Apple dibandingkan dengan semua data yang ada, yaitu 3/5. Sebagai contoh, likelihood dari P(Width = 15 | Apple) hanya muncul dalam 1 data dari semua 3 data dengan label Apple.
Kita juga dapat menghitung probabilitas invers (Not Apple, diberikan data) dengan persamaan dan hasil berikut.
Gambar 10. Perhitungan Bukan Apel dengan Naive Bayes
Jika kita menggunakan hasil di atas, probabilitas Apple lebih tinggi daripada Not Apple, artinya data akan menghasilkan Apple. Biasanya, probabilitas akan dinormalisasi untuk kedua kasus, sehingga kita selalu memiliki total probabilitas sebesar 1 dengan persamaan berikut.
Gambar 11. Perhitungan Naive Bayes yang sudah dinormalisasi
Naive Bayes sering digunakan karena kemudahan dan kesederhanaan algoritmanya. Waktu pelatihan juga cukup cepat dibandingkan dengan algoritma yang lain. Model ini populer pada use-case NLP karena berfungsi baik dalam banyak kasus NLP, seperti analisis sentimen, sentiment analysis, spam filtering, dan lain sebagainya.
Support Vector Machine (SVM)
SVM adalah algoritma klasifikasi yang cukup populer karena berhasil melampaui beberapa algoritma canggih lainnya pada kasus tertentu, seperti digits recognition. Dalam istilah yang lebih sederhana, SVM adalah pengklasifikasi yang membuat batasan untuk memisahkan kelas-kelas yang berbeda. Data disebut support vektor untuk membantu membuat batasan.
Batasan itu disebut hyperplane atau pembagi. Ini dihitung berdasarkan dataset dan dengan mengukur margin terbaik dengan memindahkan hyperplane. Ketika data berada dalam dimensi yang lebih tinggi atau ketika ada data yang tidak dapat dipisahkan secara linear, kita akan menggunakan Kernel trick untuk menemukan hyperplane.
Perhitungan untuk mengukur hyperplane memang sulit, dan saya menyarankan membaca materi berikut di sini. Berikut adalah representasi gambar SVM.
Gambar 12. Ilustrasi SVM dapat dipisahkan dari hyperplane
K-Nearest Neighbor (K-NN)
K-Nearest Neighbor atau K-NN adalah algoritma klasifikasi sederhana berbasis jarak data dan masalah optimasi Nearest Neighbor. Tidak seperti model-model sebelumnya, K-NN tidak mempelajari parameter seperti koefisien tetapi hanya menggunakan data aktual sebagai model.
Algoritma K-NN bertujuan untuk mengukur kedekatan data baru dibandingkan dengan data pelatihan yang telah dipelajari sebelumnya oleh model. Alih-alih mempelajari parameter apa pun, model menetapkan K jumlah observasi terdekat untuk mengklasifikasikan data baru.
Cara termudah untuk memahami cara kerja K-NN adalah dengan membayangkan model sebagai peta, dan setiap titik baru ditetapkan ke kelas baru dengan mayoritas jumlah K observasi terdekat menggunakan pengukuran jarak (seringkali Euclidean Distance).
Perhatikan gambar di bawah ini.
Gambar 13. Contoh model K-NN
Gambar di atas menunjukkan data aktual dari dua kelas yang berbeda (biru dan oranye). Bintang adalah data baru yang K-NN mencoba prediksi. Jika kita set K = 3, data baru akan mencari tiga data terdekat. Dengan menggunakan contoh di atas, data baru akan diklasifikasikan sebagai biru karena sebagian besar data terdekat adalah biru. Namun, jika kita meningkatkan K = 5, K-NN akan mengklasifikasikan data baru sebagai oranye karena mayoritas bergeser.
Sebagai catatan, jangan gunakan angka genap untuk K karena klasifikasi akan menjadi prediksi acak jika seri. Menemukan jumlah K yang optimal juga merupakan eksperimen, jadi cobalah mengevaluasi model pembelajaran mesin dengan metrik yang relevan.
Neural Networks adalah model machine learning yang didasarkan pada otak saraf manusia, dan model ini adalah subset dari machine learning yang fokus pada deep learning method. Secara lebih rinci, neural network biasanya terdiri dari tiga komponen simpul (node):
Mari kita lihat gambar di bawah ini untuk mendapatkan detail lebih mendalam.
Gambar 14. Model Neural Network
Secara umum, Anda bisa memiliki jumlah hidden layer yang tak terbatas untuk meningkatkan algoritma. Namun, lebih banyak node berarti daya komputasi dan waktu pelatihan yang semakin tinggi. Jadi, tidak baik jika meningkatkan jumlah layer terlalu tinggi.
Neural network menghitung prediksi dengan menghitung data melalui layer. Data diproses dalam hidden layer node di mana setiap node terdiri dari dua fungis: linear function, dan activation function. Anggaplah fungsi linear sebagai model linear, dan activation function adalah fungsi yang memperkenalkan non-linearitas ke model. Untuk menyelaraskan perhitungan, metode backpropagation digunakan.
Singkatnya, setiap data di layer input akan melewati hidden layer, dan fungsi akan membuat nilai output.
Neural network sering digunakan untuk prediksi data tidak terstruktur, seperti data gambar, teks, atau audio, karena neural network dapat mengonsumsi data ini. Ini juga memungkinkan banyak kasus penggunaan, seperti image recognition, text recognition, dll.
Model machine learning adalah algoritma yang dirancang untuk mempelajari data dan membuat output yang menyelesaikan masalah manusia. Klasifikasi dalam machine learning berkaitan dengan hasil prediksi diskrit.
Kita telah membahas tujuh algoritma klasifikasi berbeda, yaitu:
Support Vector Machine (SVM)
K-Nearest Neighbour (K-NN)
Untuk dapat menemukan pola dibalik suatu dataset agar bisa lebih bermanfaat lagi, diperlukan sebuah algoritma machine learning. Machine learning sendiri membahas tentang bagaimana cara mesin dapat belajar sendiri sehingga mesin tersebut dapat melakukan tugas tertentu tanpa terprogram secara eksplisit. Tidak seperti AI yang dapat meniru kemampuan manusia dalam merespon suatu sistem, machine learning justru mampu membuat algoritmanya sendiri untuk proses belajar. Konsep kerja machine learning dalam menggunakan algoritma yang telah terprogram adalah dengan menerima dan menganalisis data inputan untuk kemudian dapat memprediksi nilai keluaran atau output.
Berdasarkan algoritma-algoritma tersebut terdiri dari tiga tipe algoritma diantaranya Supervised Learning, Unsupervised Learning, dan Reinforcement Learning. Pada kesempatan kali ini, kami akan membahas tentang empat rekomendasi algoritma machine learning yang digunakan untuk pengklasifikasian. Jadi, jangan beranjak dan baca artikel DQLab sampai selesai, ya!
Random forest merupakan salah satu algoritma yang digunakan untuk pengklasifikasian dataset dalam jumlah besar. Klasifikasi random forest dilakukan melalui penggabungan tree dengan melakukan training dataset yang kamu miliki. Selain itu, algoritma random forest menggunakan algoritma decision tree untuk melakukan proses seleksi. Dimana tree atau pohon yang dibangun dibagi secara rekursif dari data pada kelas yang sama. Proses klasifikasi pada random forest berawal dari memecah data sampel yang ada dalam decision tree secara acak. Setelah pohon terbentuk,maka akan dilakukan voting pada setiap kelas dari data sampel. Kemudian, mengkombinasikan vote dari setiap kelas kemudian diambil vote yang paling banyak.Dengan menggunakan random forest pada klasifikasi data maka, akan menghasilkan vote yang paling baik. Pada saat proses klasifikasi selesai dilakukan, inisialisasi dilakukan dengan sebanyak data berdasarkan nilai akurasinya. Keuntungan penggunaan random forest yaitu mampu mengklasifikasi data yang memiliki atribut yang tidak lengkap,dapat digunakan untuk klasifikasi dan regresi akan tetapi tidak terlalu bagus untuk regresi, lebih cocok untuk pengklasifikasian data serta dapat digunakan untuk menangani data sampel yang banyak.
Baca juga : 3 Jenis Algoritma Machine Learning yang Dapat Digunakan di Dunia Perbankan
Naive bayes merupakan metode pengklasifikasian paling populer digunakan dengan tingkat keakuratan yang baik. Banyak penelitian tentang pengklasifikasian yang telah dilakukan dengan menggunakan algoritma ini. Berbeda dengan metode pengklasifikasian dengan logistic regression ordinal maupun nominal, pada algoritma naive bayes pengklasifikasian tidak membutuhkan adanya pemodelan maupun uji statistik. Naive bayes merupakan metode pengklasifikasian berdasarkan probabilitas sederhana dan dirancang agar dapat dipergunakan dengan asumsi antar variabel penjelas saling bebas (independen). Pada algoritma ini pembelajaran lebih ditekankan pada pengestimasian probabilitas. Keuntungan algoritma naive bayes adalah tingkat nilai error yang didapat lebih rendah ketika dataset berjumlah besar, selain itu akurasi naive bayes dan kecepatannya lebih tinggi pada saat diaplikasikan ke dalam dataset yang jumlahnya lebih besar.
Reinforcement Learning
Reinforcement learning adalah sistem machine learning yang melakukan tugas dengan memaksimalkan reward melalui tindakan tertentu. Reinforcement learning menggunakan agen untuk mengamati keadaan lingkungan tertentu dan memilih suatu keadaan untuk bertindak. Tindakan akan menghasilkan reward atau penalty tergantung pada pilihan tersebut. Reinforcement learning akan mendorong algoritma untuk menemukan strategi terbaik dalam memaksimalkan reward. Keputusan tersebut kemudian akan menjadi agen dalam suatu lingkungan tertentu.
Kita sering menggunakan reinforcement learning ketika kita tidak memiliki banyak data atau mendapatkan data dengan berinteraksi dengan lingkungan. Contoh reinforcement learning adalah self-driving car dan AI Chess.
Apa Perbedaan Antara Supervised, Unsupervised, dan Reinforcement Learning?
Machine learning adalah bidang studi dimana manusia mencoba memberikan kemampuan kepada mesin untuk belajar dari data secara eksplisit. Mesin inilah yang kita sebut model machine learning dan yang kita gunakan untuk menyelesaikan masalah kita. Ada berbagai bentuk aplikasi machine learning di industri, misalnya: face recognition machine dan email spam detection adalah aplikasi model machine learning.
Mengetahui model machine learning mana yang harus diterapkan dalam setiap use case sangat penting karena tidak semua model dapat diaplikasikan untuk setiap use case. Model yang sesuai akan meningkatkan metrik model kita.
Machine learning adalah bidang yang luas dengan banyak istilah yang digunakan di dalamnya. Untuk memberikan pemahaman yang jelas tentang apa itu algoritma klasifikasi, pertama-tama kita perlu membahas tentang tiga sistem machine learning yang berbeda berdasarkan pengawasan manusia; Supervised, Unsupervised, dan Reinforcement Learning?
Supervised Learning adalah model machine learning yang menggunakan data training dari manusia yang mencakup solusi yang diinginkan. Data training sudah berisi jawaban untuk masalah yang ingin kita selesaikan, dan mesin diharapkan meniru pola pada input data (prediktor) untuk menghasilkan output yang serupa.
Contoh data training untuk Supervised Learning adalah sebagai berikut:
Gambar 1. Data training untuk Supervised Learning
Ada dua typical tasks dari supervised learning; Klasifikasi dan Regresi. Apa perbedaan di antara keduanya? Pada dasarnya, perbedaannya berasal dari hasil prediksi.
Algoritma klasifikasi berfokus pada hasil prediksi diskrit, misalnya, prediksi Churn (keluar atau tidak), Heart Disease (terpengaruh oleh penyakit jantung atau tidak), dll.
Sebaliknya, algoritma regresi berfokus pada hasil prediksi numerik di mana hasilnya tidak terbatas pada kelas tertentu, misalnya: harga rumah, jarak mobil, penggunaan energi, dll.
Python Libraries untuk Machine Learning
Python dengan libraries, modul, dan kerangkanya bisa digunakan untuk membantu kebutuhan machine learning. Hanya saja, Anda perlu menguasai pengaplikasian Python guna mendapatkan manfaatnya dalam machine learning dan data science. Berikut adalah sepuluh rekomendasi Python libraries yang bisa Anda gunakan.
Pandas adalah library Python yang paling dikenal dan banyak digunakan. Paket ini bisa digunakan untuk menganalisis data dengan cepat, realistis, dan serbaguna. Anda dapat memakainya untuk mengombinasikan, mengelompokkan, dan mengklasifikasikan data yang berasal dari berbagai sumber, seperti Excel, SQL databases, CSV, dan sebagainya. Oleh karena itu, Pandas menjadi salah satu paket Python yang wajib dimiliki lantaran performanya yang stabil dan bersifat open source.
Selanjutnya, ada NumPy atau Numerical Python. NumPy adalah aljabar linear yang dikembangkan dalam Python guna memecahkan berbagai permasalahan terkait numerik. Banyak ahli dan pengguna yang memilih paket ini karena NumPy memiliki kemampuan untuk memecahkan permasalahan-permasalahan rumit menyangkut operasional matematika. Selain itu, NumPy juga banyak digunakan untuk menangani berbagai permasalahan lain, seperti gambar, suara, dan operasional biner lainnya.
Matplotlib adalah salah satu Python libraries yang juga sering digunakan. Paket ini dipakai untuk kepentingan visualisasi data yang melibatkan grafik, plot, histogram, dan lain-lain. Visualisasi data diperlukan untuk memahami data secara lebih mendalam sebelum melakukan data-processing dan melatihnya dalam program machine learning. Matplotlib banyak digemari karena memiliki sifat yang open source dan gratis untuk diakses.
Seaborn adalah salah satu paket yang kerap digunakan dalam Python libraries. Paket ini dirancang di atas Matplotlib dan terintegrasi dengan struktur data dari Pandas. Sama halnya dengan Matplotlib, Seaborn digunakan untuk kepentingan visualisasi data agar data mudah dipahami. Dalam machine learning, Seaborn berfungsi membaca dan memahami data-data untuk kemudian dipetakan dalam bentuk grafis statistik, sehingga dapat menghasilkan plot yang informatif.
Berikutnya adalah SciPy sebagai Python libraries yang cukup dikenal. Paket ini terdiri dari beberapa modul untuk memperoleh hasil terbaik, meliputi statistik, integrasi, hingga aljabar linear. Kelebihan dari SciPy adalah operasionalnya yang mudah untuk mengatasi persoalan matematika. Selain itu, paket ini juga berguna untuk digunakan dalam image manipulation.
Python libraries berikutnya yang tidak kalah populer adalah Scikit-learn. Paket ini menjadi salah satu yang legendaris dalam dunia machine learning. Scikit-learn dibuat atas dua Python libraries, yakni NumPy dan SciPy. Dengan demikian, fungsinya tak jauh berbeda dengan kedua libraries pokoknya, yaitu untuk memecahkan berbagai permasalahan numerik. Namun, paket ini juga bisa digunakan untuk keperluan data mining dan analisis data.
Selanjutnya ada Python libraries yang dikembangkan oleh tim Google Brain dari Google, TensorFlow. Paket ini biasa digunakan untuk memecahkan permasalahan matematika dalam berbagai aplikasi artificial intelligence atau AI. Paket ini banyak digunakan oleh berbagai pengembang lantaran mampu menjalankan komputasi dengan melibatkan tensors. Selain itu, perangkat ini juga memungkinkan penerapan komputasi di berbagai perangkat, mulai dari komputer hingga smartphone.
Keras adalah salah satu Python libraries yang cukup populer. Sebab, paket ini memudahkan para pemula untuk pembuatan prototipe. Selain itu, proses prototyping juga bisa dikatakan jadi lebih cepat. Keras dibuat atas dasar TensorFlow, CNTK, dan Theano. Kelebihan lain dari paket ini adalah mampu digunakan untuk visualisasi data selain menyusun model, mengolah dataset, dan mengevaluasi hasil akhir.
Machine learning pada dasarnya berkutat pada persoalan matematika dan statistik. Begitu juga dengan Theano yang berfungsi untuk mendefinisikan, mengevaluasi, dan mengoptimalkan berbagai himpunan multidimensi dalam matematika. Paket ini biasanya digunakan untuk program komputasi berskala besar. Namun, tidak sedikit juga yang menggunakannya untuk proyek individu.
Terakhir ada PyTorch yang menjadi produk machine learning library dari tim Facebook. Paket ini dibuat untuk menyaingi keberadaan TensorFlow karena keduanya sama-sama menggunakan tensors. Akan tetapi, PyTorch didesain untuk lebih mudah dipahami dan dioperasikan. Meski demikian, paket ini hanya dapat digunakan untuk pengembangan dan pelatihan program deep learning.
Machine learning merupakan pembelajaran mesin yang mempelajari beberapa hal di dalamnya seperti algoritma, ilmu statistik, dan lainnya. Machine learning merupakan teknologi bagian dari Artificial Intelligence. Ketika seseorang melakukan proses pengolahan data, sebagian besar orang membutuhkan algoritma machine learning untuk menyelesaikan atau mencari solusi dari permasalahan data yang ada. Algoritma machine learning pun sangat beragam dan digunakan sesuai dengan masalah data yang sesuai.
Algoritma sendiri merupakan suatu proses langkah demi langkah yang tersusun untuk menyelesaikan permasalahan. Algoritma machine learning sendiri sangat beragam dan sudah sering digunakan untuk menyelesaikan permasalahan data dalam berbagai bidang seperti kesehatan, pendidikan, bisnis, keuangan, dan masih banyak lainnya. Kira-kira apa saja ya algoritma machine learning yang cukup sering digunakan dan bagaimana cara kerja machine learning? Yuk, simak artikel berikut ini!
Naive Bayes merupakan salah satu algoritma supervised learning yang sederhana dan cukup sering digunakan. Algoritma ini menggunakan dasar Teori Bayes di dalamnya. Algoritma ini memiliki data training (data yang sudah terdapat label kelas) dan data testing (data yang belum memiliki label kelas). Algoritma Naive Bayes bekerja dengan cara memaksimalkan nilai suatu kelas. Kelas yang memiliki probabilitas tertinggi akan masuk ke dalam salah satu dari label-label yang tersedia.
Baca juga : 3 Jenis Algoritma Machine Learning yang Dapat Digunakan di Dunia Perbankan
Jika pada algoritma supervised learning salah satu tujuan kita adalah untuk mengetahui label kelas pada data, maka pada unsupervised learning tidak berlaku demikian. K-Means merupakan salah satu algoritma supervised learning yang mana cara kerjanya adalah mengklaster atau mengelompokkan data sesuai dengan karakteristik atau kemiripan data menjadi beberapa klaster sesuai dengan nilai k yang telah ditentukan. Pada algoritma ini dibutuhkan centroid atau nilai pusat serta menghitung jarak kedekatan data dengan centroid. Algoritma ini dilakukan secara berulang sampai tidak ada perubahan anggota dalam masing-masing kelompok.
KNN atau K-Nearest Neighbour merupakan salah satu algoritma supervised learning yang mengklasifikasikan atau mengelompokkan data ke dalam beberapa kelompok berdasarkan kemiripan sifat dari data. Algoritma ini hampir mirip dengan algoritma K-Means, yang membedakan adalah pada K-Means melakukan proses clustering sedangkan pada KNN melakukan proses klasifikasi. Terkadang orang menyebut algoritma ini dengan sebutan algoritma malas dikarenakan pada algoritma ini tidak mempelajari cara mengkategorikan data akan tetapi hanya mengingat data yang sudah ada.